Access Developer 39
Searchable Document Index, MS Word Automation
Welcome
This class is all about building a searchable document index in Microsoft Access. We are going to learn how to use Microsoft Word Automation to take a file - any file type that Word can read, including DOCX and PDF - and then automatically convert that document to text so we can read it into our Access database. We will then parse the text of that document, index each word, and store a count of each word for each document. We'll also spend more time on Recordsets, learning how to search within an open Recordset using the FindFirst and NoMatch commands.
Resources
Topics Covered
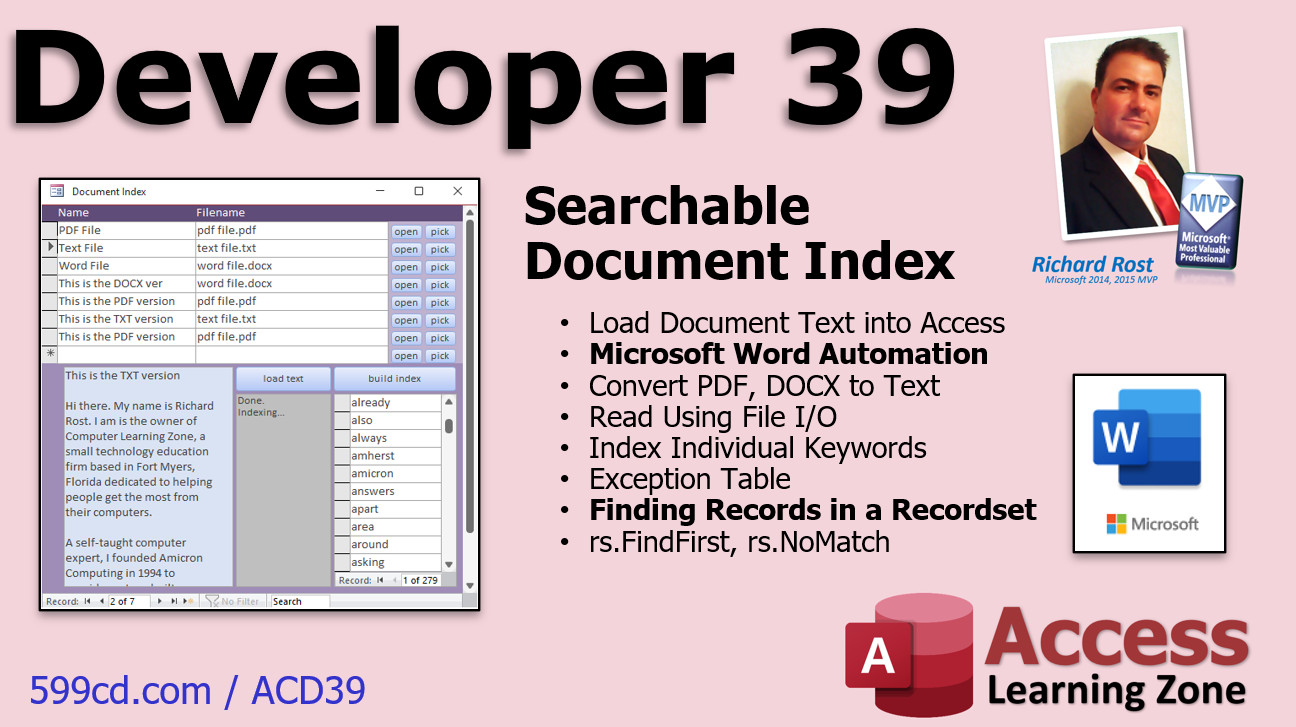
In Lesson 1, we will begin building our searchable document index. We'll create the needed tables and forms. We'll review how we can use FollowHyperlink to open any file. We'll build a search box to show only documents that contain our search term. We'll assign documents to customers, and then open a list of just that customer's documents from the customer form.

In Lesson 2, we will add a button so that we can browse and pick a file. We will then use Microsoft Word Automation so that we can open the document in Word in the background using VBA, copy that document's text, and paste it into our database. This will work with any file type that Word supports: DOC, DOCX, PDF, TXT, and more.

In Lesson 3, we will talk about the reasons why it's beneficial to create your own index instead of just relying on Access to index the field (hint: one of the major reasons is to save space). We'll talk about the limitations of long text fields, and I'll show how you to overcome the 64k limitation on text boxes. Then we'll switch from using copy/paste to get the text data from Word and actually make Word convert the document into a text file. We'll use VBA File I/O which we learned in Developer 30 to read the text directly into our database.

In Lesson 4, we will build our own keyword index. We'll parse the text of each document and store each keyword in a separate index table. This saves a ton of space. We'll review using a composite key to prevent duplicates.

In Lesson 5, we will make a subform to show the keywords for each document. We'll build an exception table so that we don't waste time and space indexing connector words (the, an, them, he, she, etc.) We'll improve upon our search algorithm, changing the recordsource property for our document form if the user is doing a search vs. just browsing, editing, or adding.

In Lesson 6, we will display the percent completed while building an index as large documents can take a few minutes to parse. We'll add an abort checkbox in case the user gets tired of waiting. We'll add a word count for each keyword so you can see which documents may be more relevant for certain keywords than others. We'll learn how to search for records while inside an active recordset using the FindFirst and NoMatch commands. Finally, we'll spend some time optimizing our AddToIndex loop to speed it up as much as possible.

Enroll Today
Enroll now so that you watch these lessons, learn with us, post questions, and more!

Questions?
Please feel free to post your questions or comments below. If you are not sure as to whether or not this product will meet your needs, I'd rather help you before you buy it. Remember, all sales are final. Thank you.
 Keywords Keywords
microsoft access, access 2016, access 2019, access 2021, access 365, ms access, #msaccess, #microsoftaccess, #help, #howto, #tutorial, #instruction, #learn, #lesson, #training, #database, Searchable Document Index, Microsoft Word Automation, Convert PDF to TXT, DOCX to Text, Index Individual Keywords, rs.FindFirst, rs.NoMatch, Limitations of Long Text Fields, Overcome 64k Limitation, WordDoc.SaveAs2, wdFormatText, Exception Table, Display Percent Completed, Abort, Word Count, Finding Records in a Recordset, rs.FindFirst, rs.NoMatch, dbOpenDynaset
More InformationTranscript Welcome to Microsoft Access Developer Level 39 brought to you by AccessLearningZone.com. I am your instructor, Richard Rost.
In today's class, we are going to focus on building a searchable document index. That's where we can take different documents and load the text of those documents into our database so that we can search on the keywords. For example, if you want to find which customers have documents that contain the word "elephant," then it is a very easy search to do.
We are going to learn how to use Microsoft Word Automation. In VBA, we will be able to click a button, have Microsoft Word open up in the background, and read in the file. Whether it's a PDF, a text file, a Word document, or any document type that Word supports, you can do this with it.
We will take that document, save it as text, then pull the text into our Access database and index all the keywords. We will build an exception table so we do not have to bother indexing words such as "the" or "in" or "at."
Then we will work with recordsets some more. I know you love recordsets. I spent a lot of time on recordsets in earlier lessons. We will learn how to find records while a recordset is open, and we'll learn about the NoMatch property.
This lesson follows Access Developer 38 and everything that comes before it. I strongly recommend you have completed my Beginner, Expert, Advanced, and Developer series before continuing with this lesson. My lessons are meant to be taken one after the other. Each one builds on the one that came before it.
Look at this page. If you do not believe me, read that.
I will be using Microsoft Access 365. It is currently July of 2022, so it is roughly equivalent to Microsoft Access 2021. However, the lessons covered in this course should be applicable going back to, I am going to say, Access 2007. If you are using something earlier than that, forget it. Access 2007 and on - all of that should work just fine with what we are covering today.
If you have questions about the material covered in today's class, scroll down to the bottom of the page that you are watching this on and post a comment right there on the lesson page. If you have other questions that do not necessarily pertain to the topics covered today but are about other Access questions, or Excel or Word, post them in the forums on my website.
Let's take a few minutes and cover exactly what we are going to do in today's class.
In lesson one, we are going to begin building a document index, a searchable document index. We are going to create the table to hold this information. We are going to use FollowHyperlink to open files. We have done that before, so that is nothing new. We are going to then copy and paste the document text into the index table and create a search box so that we can search for documents that have any particular keywords in them.
Then we will assign each document to customers so you can go to the customer's record and open up any documents related to that customer.
In lesson two, we are continuing on with our document index. We are going to make a button to browse and pick a file. We will automatically load that document into Microsoft Word in the background using some VBA and some Word Automation. Then we will be able to convert any PDF file, Word document, or text file into plain text that we can pull into our Access database. That is all covered in lesson two.
In lesson three, we are continuing with the document index. We are going to learn some reasons why you would want to build your own index. There are a bunch of reasons why, and we will cover them in this lesson. There are a lot of limitations with long text fields. One of them is you cannot edit a long text field of more than 64k. It is about 4,000 characters. We are going to learn how to use file input/output from Access Developer 30 to import text files directly.
We will open up Word, save the Word doc or the PDF as a text file, then use file I/O to read that in instead of copying and pasting it. All of that is covered in lesson three.
In lesson four, we are continuing on with the document index. We are going to actually build the index tables that hold the data for all the keywords. The index table has the list of keywords in it just once. Then we will build a junction table to track which keywords are in which documents.
We will use a composite key to prevent duplicates. We will write an AddToIndex subroutine, filter out unnecessary characters, and much more.
In lesson five, we are going to set up our document index queue and our document index subform, this little guy right here. You can click on a document and see whatever words are in that document down below. We will set up our exception table, which is a list of words you do not care to index, like "that," "them," "there," "they," "about," "it's," and similar words.
Then we will make sure that the search now works, taking the index table into consideration. This means we have to change the record source when we go between not searching or showing all the documents. It is a little tricky. A lot of good query stuff in this lesson, and we are going to cover that all in lesson five.
Finally, in lesson six, we are going to finish up this document index. We are going to display the percent completed right there. You are going to see "73 completed" while this index is building, which is great for larger documents that take a while, like the big one we did down here. It could take a few minutes to compile.
That is what we are going to spend some time with at the end of the lesson. We are going to optimize this, so we are going to try and replace some of this SQL we have been writing with recordsets. We are going to use FindFirst and NoMatch, which is new recordset material. I know you love recordsets.
We are going to open DB, open Dinosaur, which I forgot about when I was writing the code the first time. I got an error message, so we have to fix it. I know you love my error messages too. We are going to add a word count. That is one of the other reasons for adding the recordset loop here. So you can see, for example, the word "computer" was in this document nine times, and the word "people" is in it seven times.
We will do a lot more recordset coding. This will conclude our document index, but this lesson has a lot of cool stuff in it, and some new material.
Here we go. Intro In this lesson, we will build a searchable document index using Microsoft Access, learning how to import document text—including from Word documents, PDFs, and text files—directly into your database. We will work with Microsoft Word Automation in VBA, set up tables to store documents, keywords, and exceptions, and create features to link documents to customers. You will learn techniques for indexing keywords, managing large text fields, handling query optimization, and using recordsets with properties like NoMatch and FindFirst. We will also add progress tracking as the index is built. This is Microsoft Access Developer 39. Quiz Q1. What is the main topic covered in this lesson of Access Developer Level 39?
A. Building a searchable document index in Access
B. Designing forms for inventory management
C. Creating parameter queries in Access
D. Importing spreadsheets into Access databases
Q2. What tool is used to automate the loading of document files in the background?
A. PowerPoint Automation
B. Word Automation in VBA
C. Excel Automation
D. Outlook Automation
Q3. Which of the following document types can be processed using the techniques taught in this lesson?
A. Only Word documents
B. Only PDF files
C. Only text files
D. Any document type Word supports
Q4. Why is an exception table built as part of the document index project?
A. To store backup copies of all documents
B. To prevent indexing of common words like "the" and "in"
C. To log errors encountered during automation
D. To save hyperlinks to external documents
Q5. What is the role of recordsets in this lesson?
A. Managing user accounts
B. Navigating through records and finding specific data
C. Creating new tables
D. Printing reports
Q6. What happens in lesson one of this series?
A. Finalizes the document index with advanced query optimization
B. Begins building the searchable document index and creates the necessary table
C. Explains composite keys in detail
D. Focuses on customer management forms
Q7. When loading a document, what is done to convert it into a searchable format in Access?
A. Save as image and extract text from the image
B. Save as plain text and import the text into the database
C. Convert directly into Excel
D. Print and scan the document
Q8. What limitation of long text fields in Access is discussed in the lesson?
A. They cannot be used as indexes
B. They are limited to roughly 4,000 characters for editing
C. They are read-only by default
D. They cannot store numbers
Q9. What is the purpose of the junction table in the document indexing system?
A. To connect users with their permissions
B. To link keywords to documents
C. To store customer addresses
D. To log import errors
Q10. In order to optimize performance, what recordset methods are highlighted in this lesson?
A. MoveNext and Delete
B. FindFirst and NoMatch
C. AddNew and Update
D. Close and Requery
Q11. What feature is added in lesson six to help users see indexing progress?
A. Error log window
B. Percent completed display
C. Document preview pane
D. PDF conversion error summary
Q12. What is the purpose of showing a word count for each keyword in the document?
A. To identify the length of the document
B. To show how many times each word appears in a document
C. To measure file size
D. To create a misspelling list
Q13. Which Access versions are stated to be compatible with the techniques taught in this lesson?
A. Access 2010 and earlier only
B. Access 2003 and Access 97
C. Access 2007 and later
D. Access XP only
Q14. What should students do if they have questions specific to the class material?
A. Email Richard directly
B. Post a comment at the bottom of the lesson page
C. Search in the Microsoft Support forums
D. Ask during office hours
Q15. Why does the instructor recommend following the course sequentially?
A. Each lesson has unrelated topics
B. Lessons build on previous material
C. There are discounts for following in order
D. Later lessons are only available after a test
Answers: 1-A; 2-B; 3-D; 4-B; 5-B; 6-B; 7-B; 8-B; 9-B; 10-B; 11-B; 12-B; 13-C; 14-B; 15-B
DISCLAIMER: Quiz questions are AI generated. If you find any that are wrong, don't make sense, or aren't related to the video topic at hand, then please post a comment and let me know. Thanks. Summary Today's video from Access Learning Zone takes us into Microsoft Access Developer Level 39. In this class, I am going to show you how to build a searchable document index in your Access database. This feature provides an easy way to load the text of various documents, such as PDFs, Word files, or text documents, directly into your database, and then search for specific keywords, like "elephant," within those documents.
One of the main areas we will focus on today is using Microsoft Word Automation with VBA. This lets us set up a process so that when a button is pressed, Word will quietly open in the background and extract the text from a given file. Word supports a wide range of file types, not just its own DOCX format, but also PDFs and plain text files. So, by automating Word, we can convert any compatible document to plain text, capture that text, and then save it into our Access database for later searching and indexing.
To organize our search capabilities, we will also build an exception table. This will hold common words like "the," "in," or "at" that usually do not add meaning to our searches, so we can ignore indexing them.
There will be plenty of work with recordsets in this lesson. I know we have covered recordsets before, but today, we will go deeper. We will look at how to find records while a recordset is open, and I will explain the use of the NoMatch property, which helps us check whether a search in a recordset finds a matching record.
This course builds on everything from Access Developer 38 and all the previous classes. I really recommend that you complete my Beginner, Expert, Advanced, and earlier Developer series before attempting this lesson, since each one builds directly on the knowledge and skills covered in the previous one. Skipping ahead can make things confusing.
For reference, I am using Microsoft Access 365 as of July 2022, but you should have no trouble following along if you have Access 2007 or later. The content in today's class is compatible with all recent versions back to Access 2007.
If you have questions specific to today's class, you can post them directly on the lesson page. For other Access, Excel, or Word questions that are not about this lesson, please use the forums on my website.
Here is an outline of what we will do in each lesson section:
In lesson one, we will start constructing the searchable document index. This includes building the table that holds our document data, and learning to open files using FollowHyperlink. Next, we will copy and paste document text into our index table and create a search box to filter documents based on keywords. We will also link documents to specific customer records for easy access.
In lesson two, the focus remains on the document index. We will create a button to browse for a file and then automate the process of loading that file into Word in the background. Once the document is open, we will convert it to plain text so we can import it into Access, making it searchable.
Lesson three explains why you might want to build your own index, instead of relying on native Access features. I'll cover issues like the limitations of long text fields, including editing restrictions on fields over a certain size. You will also learn to use file input and output methods from Access Developer 30, allowing you to import text files directly. We will use Word to save documents as plain text files, then use file input/output routines to read those files in, rather than relying solely on copy and paste.
Lesson four is where we really flesh out the underlying data structure. We'll create index tables that store all unique keywords, and a junction table to track which keywords appear in which documents. Using a composite key ensures that duplicates are avoided. We'll also write a routine to add words to the index, filtering out unnecessary characters and other unwanted data.
In lesson five, we set up our document index queue and create a subform so you can click on any document and see a list of the keywords it contains. The exception table comes into play again here, so we can prevent words like "that," "them," "there," and so on from being indexed. We will also make the search functionality aware of the new index tables, which means updating record sources dynamically based on whether a search is active. This lesson involves some advanced query work.
In our final section, lesson six, we will wrap up the document index feature. I will show you how to display real-time progress while building the index, such as showing that 73 words have been indexed so far, which is especially helpful with large documents that take time to process. We will also work on optimizing the indexer, including replacing some SQL with more robust recordset methods, and introducing FindFirst and NoMatch for better control. Error handling will be covered too, including a look at an error I encountered when forgetting to open the database, and how to fix it. We will add a feature to count word occurrences per document, so you can see how many times each word appears in a document.
By the end of this class, you will have a fully functional document indexing and searching tool for your Access database, with several advanced features and techniques to help you work with documents and keywords efficiently.
You can find a complete video tutorial with step-by-step instructions on everything discussed here on my website at the link below. Live long and prosper, my friends. Topic List Building a searchable document index in Access
Creating tables for document indexing
Using FollowHyperlink to open files
Copying and pasting document text into index table
Creating a search box for document keywords
Assigning documents to customers
Creating a button to browse and pick a file
Automating Word to load documents via VBA
Converting PDF, Word, or text files to plain text
Importing text files using file input output
Saving Word or PDF as text for import
Building index and junction tables for keywords
Using composite keys to prevent duplicates
Writing an AddToIndex subroutine
Filtering out unnecessary characters from keywords
Setting up exception table for ignored words
Configuring subform to display indexed words
Updating search to use the keyword index
Dynamically changing record source for search
Displaying percent completed during indexing
Optimizing document indexing with recordsets
Using FindFirst and NoMatch with recordsets
Adding word count statistics per document Primary Topics document indexing, Microsoft Access VBA, Microsoft Word Automation, keyword extraction, searchable database design, exception table setup, recordsets, composite keys, file input/output, query optimization
Secondary Topics customer-document assignment, search forms, query filtering, error handling, word count tracking
|



